No alarm. There were a few nights when i’ve tried Dreem 2 smart alarm feature, but almost all days i’ve woke up naturally.
Also i’ve used sleep mask to make sure morning sun do not disturb my sleep and foam earplugs which was cut with scissors to fit my ears without pressure.
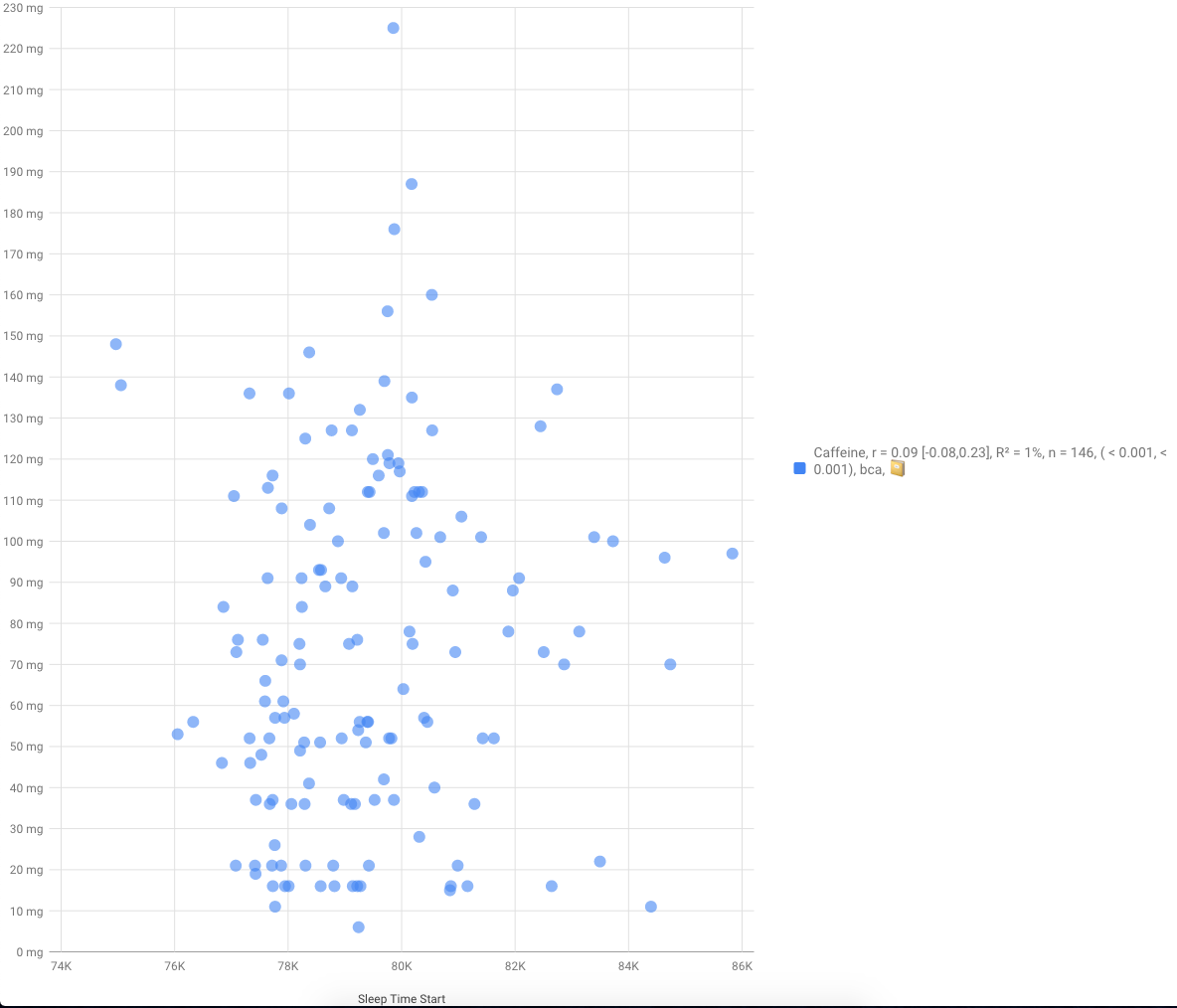
Yes, that was the same timeframe. I’m planning to model TST ~ caffeine + bedtime to distinct effects. But since i’m trying to have strict schedule around ~22:00, i dont think that caffeine influenced that time.
I’ve checked for correlation between caffeine and bedtime using bootstrap and didnt found it, CI is [-0.08,0.23] which crossing 0 with n=146
(caffeine is y, bedtime is x, in seconds from 00:00)
As you can see above, i havent found correlation between caffeine and bedtime start. There were enough low caffeine days but scatterplot didnt reveals a connection…
Right now i’m lowering my dose and will continue to monitor my sleep, but Dreem 2 after about 1 year of use is dying on me and i cant find casual alternative to precisely track my sleep (eeg)
Also it’s worth noting, that i start my preparations ~1 hour before sleep: - dim the light, wear blue glasses, read ebook and doing something calm & relax for most of days.
I’ve did extended analysis of which factors influence my sleep, if somebody interested details is here
In short: caffeine, bedtime start, sickness, vitamin D3 and negative emotions statistically significantly and independently influence my sleep. I’ll lower my caffeine intake, will go sleep earlier, will take D3 every other morning, and looking for ways to reduce my stress.
Fascinating work in this thread so far! Looking forward to diving deeply into it all.
I recently did an massive observational study on my sleep behaviour over 472 nights, relating it to data about my eating windows, mood, exercise, location, activity, heart rate, habits, weather, etc. If you’re interested in the details, you can read the summary here or the full paper here.
The idea was to use observational data (and some clever techniques) to narrow down the key factors that interfere with sleep quality. Those can then be explored in controlled experiments (like @sskaye’s pre-registered melatonin study).
These were the most predictive features in my final model. The 16 final features are a reduced subset of the 308 initial features that were explored throughout the observational study, yet they explain the majority of the variation in sleep quality. There are many caveats about interpreting these that I discuss extensively in Sections 9.5 and 10.5 of the paper.
Some of the features are expected — travelling, eating windows, previous sleep, and melatonin
are all known to affect sleep quality. But the direction of some of these effects was
unexpected. E.g. melatonin consumption is associated with a decrease in sleep quality,
when research suggests it should be an increase. The previous night’s sleep quantity also
has an unexpected decrease on the present night’s sleep quality. Perhaps there is some
kind of trade-off between sleep quality and sleep quantity on successive nights? These unexpected
directions might just be artefacts of the study design, or could be idiosyncrasies in my
sleep patterns.
On the other hand, some of the final 16 features were very much unexpected. Specifically, the lag
in the features. It is not intuitive that pleasure reading and barometric pressure from many days
prior could affect the current night’s sleep. It is also strange that location changes from an entire
week prior are still predictive of the current night’s sleep. One explanation is that these features
merely correlate with other (unmeasured) variables that influence sleep quality, and that this is
being captured by the model. Another (complementary) explanation is that the sparsity effect
of the Lasso model caused it to discard all but one feature from each set of highly-correlated
features.
I’m hoping to write up a more accessible discussion of the study and my findings. I’ll post it on the forum when it’s ready.
Very interesting! This is a small detail but I think of interest to other QS Forum readers: Say something about your experience using the Nomie app. Did it perform as expected? Was it a good solution for some or all of the active observations?
I’ve read full paper and it looks like a very well guide for serious QS’ers.
When i read about previous day sleep impact, i’ve immediately did lasso on my data, sleep time from previous night survived and resulted in increase in adjusted-rsquared from 0.24 to 0.28. p-value were significant in final lm. significant improvement
the idea of markov unfolding and overcoming missing data is pretty interesting, i’m going to try it when my noob skill in statistics will be improved Actually i did that in some degree, but not in a solid way like you
The bedtime feature had a strong negative correlation with the target (r ≈−0.6), which is likely
because it is considered as part of the ideal sleep window calculation that comprises 10% of the
sleep score. It was important to remove features like this from the dataset prior to training the
model, in order to prevent data leaks
That looks weird for me. Bedtime isnt a measure of sleep quality - it’s something that affect sleep quality. Maybe it’s better to remove bedtime from sleep score (since you know the oura formula & weights, that’s shouldnt be a problem) and keep bedtime in dataset as a featuire which may influence sleep quality.
Keeping bedtime in a final feature (sleep score) have another problem - since the bedtime sometimes defined by your decision and not by features in data set, sleep quality will be distorted by including bedtime.
according to my data oura sleep score is very noisy variable.
Sleep stages are pretty poorly detected (in my case)
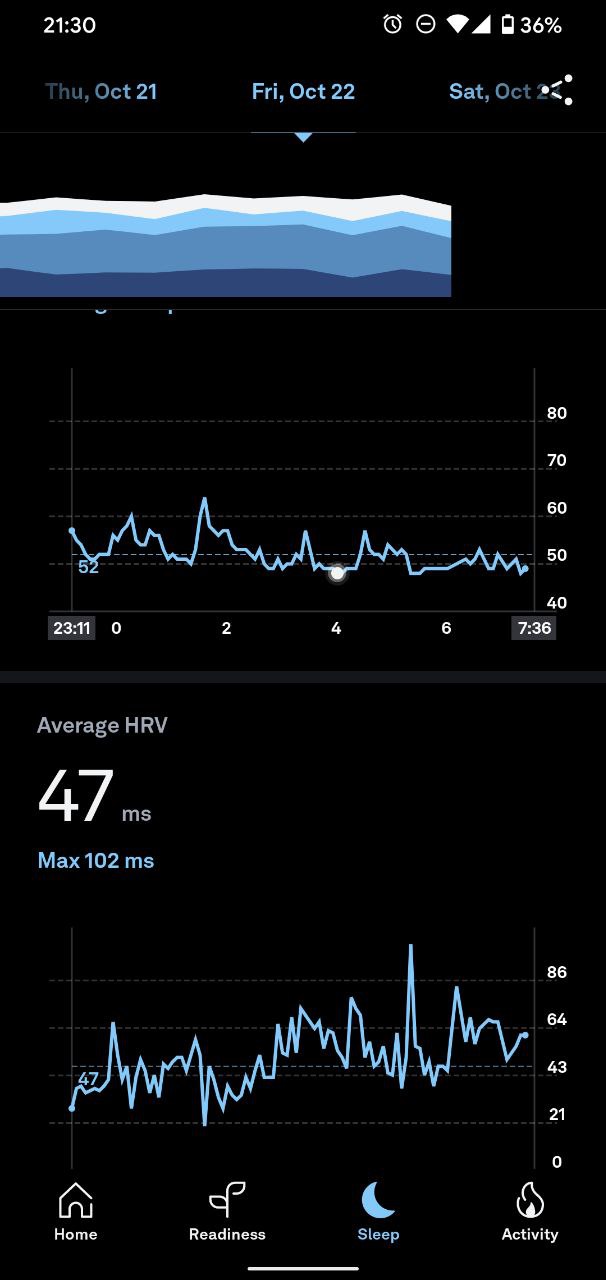
Total sleep time also poorly detected - i did bland altman for 140 nights of data and found poor limits of agreement and huge bias
There is -24 minutes bias and -144 minutes to +95 minutes limit of agreement.
I’ve also did correlation analysis for restlesness score but even this score didnt correlate (<0.2) with awake time, awake count, position changes count from eeg device. Same for sleep latency
So in a total - sleep stages, total sleep time and restlessness seems to have bad signal to noise ratio and i’m not sure in what degree oura sleep score represents sleep quality. There should be some useful signal, but data above raises a lot of questions. Only total time in bed looks acceptable
Thanks for work you have done i hope there will be more n=1 papers with deep dive like that
I’ve been using Nomie for probably 5 or 6 years now and really like it. At points, I was using it for almost all of my active quantitative logging. I really like the speed and flexibility it offers.
But, over the years, developer interest seems to have waned. That scared me off. All seasoned QS enthusiasts know that feeling of a tool they’ve been using suddenly going offline and ruining their experiments*.
For the past 2 years, I’ve only been using Nomie for caffeine and alcohol tracking. It’s been particularly great for that! I put the app on the bottom right of my homescreen and became very fast and discrete at logging whenever I had a coffee or an alcoholic drink with a quick tap. For those trackers in particular, you want something that’s super fast and minimal so that it’s not distracting in social situations. Nomie works really well for that — only my immediate family and SO even notice it.
So Nomie is great, but I feel hesitant to rely on it because its support status seems to constantly be changing.
*This actually happened to me with AWARE during the Quantified Sleep experiment, which required me to do some non-trivial workarounds to salvage my data.
Thanks for checking out the paper, Max! I’m glad to hear that it prompted some ideas for your own research . It’s very exciting to get feedback from other QS practitioners about how well techniques generalise across datasets, so thank you for all the details!
When i read about previous day sleep impact, i’ve immediately did lasso on my data, sleep time from previous night survived and resulted in increase in adjusted-rsquared from 0.24 to 0.28.
Lagging features are surprisingly powerful, but (as I mention in the paper) there’s a lot of optimisation to be done in how to incorporate information from lags >1. But features with a lag of 1 are already just an easy way to boost predictive performance (and better understand the time series). I’m glad that worked for your model, but bear in mind that you’ve also added more parameters (lowering bias and increasing variance). Are those adjusted R^2 values on a validation set?
the idea of markov unfolding and overcoming missing data is pretty interesting, i’m going to try it when my noob skill in statistics will be improved…
Much of the complexity in my paper was because I was comparing these techniques to baseline, which requires some fiddly tricks to prevent data leaking. In terms of actually implementing them, it shouldn’t be too complex. Markov unfolding is a bit conceptually complex, but the actual implementation is pretty simple (in Python with Pandas), so long as your dataframe is already in the right format:
def markov_unfolding(df: pd.DataFrame, length=7):
""" Creates `length` new features for each column, corresponding to time lag.
"""
_df = df.copy() # Make a copy of original data
# Loop over numeric columns (except the target feature named 'target')
numeric_cols = _df.select_dtypes(np.number).columns
for c in [col for col in numeric_cols if 'target' not in col]:
# Apply shifts of up to `length` and stack them onto the new dataframe
for i in range(1, length+1):
_df[f'{c}_-{i}day'] = _df[c].shift(i)
return _df
As for the missing data imputation, there are existing implementations in both R and Python for this. They handle most of the complexity for us .
That looks weird for me. Bedtime isnt a measure of sleep quality - it’s something that affect sleep quality. Maybe it’s better to remove bedtime from sleep score (since you know the oura formula & weights, that’s shouldnt be a problem) and keep bedtime in dataset as a featuire which may influence sleep quality.
You’re definitely onto something here. I did consider extracting parts of the Oura score to construct a more tailored target feature. I decided against it because I wanted to keep the approach general (so that other Oura users could replicate my methods more directly). It would be interesting to look at how much noise vs. signal each component of the Oura sleep score contributes — perhaps I’ll tackle this one day in the follow-up work!
Keeping bedtime in a final feature (sleep score) have another problem - since the bedtime sometimes defined by your decision and not by features in data set, sleep quality will be distorted by including bedtime.
Exactly! This speaks to one of the major challenges of observational QS studies: the feedback loops make it really hard to figure out candidates for causal relationships. There is also quite a bit of variation between individuals here, I think. For instance, I’ve always struggled with insomnia and having a consistent sleep schedule. For me, my bedtime seems out of my control, so it made more sense to treat it as (part of) the dependent variable. But for someone who can fall asleep easily at whatever time they intend do, it’s much more of an independent variable (and therefore a feature). These nuanced decisions are part of why designing QS studies is so very challenging and bespoke to each individual. But maybe that’s also part of the fun!
according to my data oura sleep score is very noisy variable.
Yes, I’d say this is expected. Sleep quality (even in the abstract sense) is quite noisy as there are so many factors that contribute to it and sleep is still so minimally understood. Then we add in the noise introduced by sensors and using model predictions as proxy measures, etc.
Sleep stages are pretty poorly detected
This seems to be consistent with the literature. Though I’m not sure that we even have good ways of measuring sleep stages in a lab — all our sensors are “guessing” in some sense. This obviously contributes to the high noise.
Total sleep time also poorly detected
This surprises me My own experiences, comparisons by other QSers, and lab studies all find sleep duration (onset, interruptions, offset) to be quite accurate.
Am I correct that you compared the Oura with a Dreem 2 headband? Both devices will have some noise, surely, but we can’t know which just from the Bland Altman.
So in a total - sleep stages, total sleep time and restlessness seems to have bad signal to noise ratio and i’m not sure in what degree oura sleep score represents sleep quality. There should be some useful signal, but data above raises a lot of questions.
Unfortunately, these things are all hard to measure (even with lab-grade polysomnography equipment), so we have to just deal with noisy variables here.
One workaround that might apply to you would be to build 2 identical explanatory models: one model using the Oura sleep score as a target, and one using the Dreem score as a target. That way, we know both are noisy, but any agreement between the feature importance/direction in the models is probably robust. I’d be very interested in seeing how consistent the models are, despite the targets not being in agreement.
Thanks for work you have done i hope there will be more n=1 papers with deep dive like that
Thanks for all the great feedback and for replicating some of the analysis! I’m looking forward to seeing your future experiments!
Are those adjusted R^2 values on a validation set?
I did LOOCV, 10 fold CV, validation set approach (1/2) and finally on a whole sample. In each method adjusted R^2 increased by 3-4%
thanks, my code in R looks pretty similar to yours
But the circadian rhytm have influence on sleep, so when you shift your bedtime (even if you fall asleep fast) it may affect you sleep. Going to sleep at 21:00 in one day may result different sleep quality compared to sleep which started at 23:00 on another day. And decision to go to bed at 21:00 / 23:00 may be driven by something not included in model.
That’s correct, but sleep stages defined by eeg patterns (spindles, k-complexes etc). In case of ring it tries to predict stages without eeg which results in poor agreement with eeg devices. EEG devices also not perfect, but agree well between themselves which is a good sign of measuring same thing.
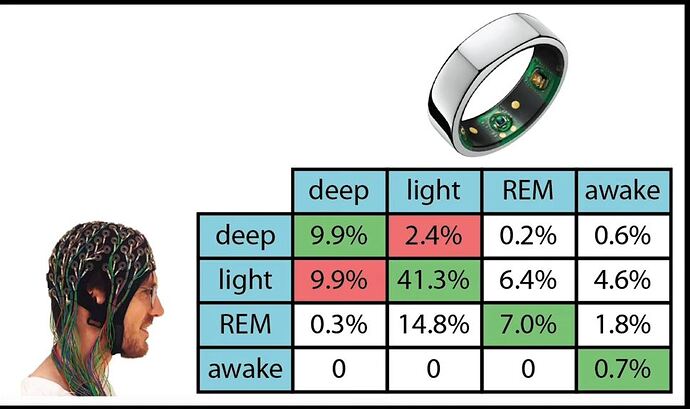
This comparison shows poor agreement. Total sleep time is Time in bed minus awake time.
As you can see oura marked 0.6%+4.6%+1.8%+0.7% = 7.7% as awake time from sleep. Only 0.7% or 0.7/7.7 = 9% of awake time was detected. 91% of awake time gone to light/rem/deep. If we assume time in bed is perfect and awake time is a total mess, how can we get total sleep time? We deduct a wrong time from time in bed, which result in wrong total sleep time. Also you can see here that 50% of deep sleep was detected incorrectly. Same for rem.
This study also shows poor accuracy. They seems to use 30 minute wrapping because not want to report poor accuracy. There is no 87% agreement with PSG on total sleep time. Diff between psg and oura is less than 30 minutes ~87% for total sleep time and awake time. Imagine 25 minute difference for awake time during night - this paper treats this difference as agreement. Imagine total sleep time of 7 hours in PSG and 7h 25 minutes for oura - this doesnt looks like good agreement but paper treats this difference as agreement.
Yes. Right now i’m using fitbit charge 4 and 5, oura, withings sleep, dreem 2 and manually asess my sleep every morning (before looking at any devices). I’m planning to post my results soon. Using dreem as a reference device, manual asessment of total sleep time outperfroms other non-eeg devices (~60 nights of data), so i’m pretty sceptical on total sleep time from non-eeg wearables (we can think of brain as an eeg device ).
I trust dreem more because they validated eeg signal quality (dry eeg seems not perfect, but good enough) and showed 85% agreement with PSG on sleep staging. Quantified Scientist got same results. I didnt see same level of sleep quality detection in any of oura papers / reviews. I hope i’m not biased here
That’s right, but more signal = better quality of outcome response and bigger chance to detect associations with predictors.
Dreem doesnt have sleep score and we cant use oura sleep score formula because there is no restlessness parameter. Dreem measure “restlessness” directly and report awakening count and position changes during night. We may try to use same formula as oura, but replace restlessness by standartized awakenings count, scaled to 0-100. But why we should use that formula? How did they get it? Does it validated in some degree and represents sleep quality? I cant find answer to that question.
I’ve found interesting this kind of factor analysis did by Gwern, where him look for latent variables and categorize them as “sleep quantity” and “insomnia”.
Thanks. When are you planning to show your next paper? I’m ready to read now
This comparison shows poor agreement. Total sleep time is Time in bed minus awake time. […] This study also shows poor accuracy. […] Imagine total sleep time of 7 hours in PSG and 7h 25 minutes for oura - this doesnt looks like good agreement but paper treats this difference as agreement.
I think we might be talking past each other here. I would interpret both the lab results and Quantified Scientist’s as showing good sleep detection accuracy. It seems like you would expect it to be a lot closer? I guess it also depends what your goals are in QS.
Looking at the time-series from Rob’s analysis, it seems that the wake/sleep binary classification aligns pretty well. As I point out in the paper, this is pretty good for a device that’s so uninstrusive. I mean, are humans even this accurate? I’m not sure that I’d get better accuracy by having a sleep scientist label timestamps of a video of me sleeping. But maybe my intuitions are wrong here? I totally see how EEG can detect REM sleep (and why the Oura struggles), but light/wake classification is much less obvious. And using HRV/motion data can probably detect a lot more restless behaviour than EEG, no?
What I really like about the Oura ring is that I have virtually no missing data and no disruption to my natural behaviour. I literally wear it constantly. This means that I have data from aeroplanes and couches and trains and all sorts of occasions where I wouldn’t have worn a headband. As a result, I have >1000 nights of Oura data under a wide variety of situations. For my goals, having 1000 nights of noisy-but-varied data is much more useful than 500 nights of slightly-more-accurate data that may be biased to occasions where I could/bothered to wear the EEG device. That’s definitely a trade-off and there are advantages and drawbacks to both.
Much further up this thread you said:
Right now i’m doing some nbacking and spaced repetition before sleep to check if it increase my REM sleep.
Given those experiments, I totally agree that the Oura ring is not accurate enough — especially with REM classification.
I’m planning to post my results soon. Using dreem as a reference device, manual asessment of total sleep time outperfroms other non-eeg devices (~60 nights of data), so i’m pretty sceptical on total sleep time from non-eeg wearables
I’m very interested to see these results! Especially with your manual assessment. Sure, it’s not that hard to estimate to within 10-15 minutes when you went to sleep and within 5 minutes when you woke up. But what about disturbed sleep during the night? I find that very difficult to estimate (which is why I rely on devices). Perhaps we have quite different sleep profiles/habits? Or maybe I misunderstood what you meant. But I’m looking forward to your results!
Dreem doesnt have sleep score and we cant use oura sleep score formula because there is no restlessness parameter.
I think it would be good to create your own scoring function anyway. In my study, I had a couple of reasons to stick with the built-in Oura score. For a comparison across devices (and for the types of experiments you seem to be interested in), it makes a lot of sense to devise your own composite score — it could even include some subjective measures of sleep.
This is something I intend to do in my future analyses, particularly focussing on things I personally care more about, like feeling rested and energised when I wake up.
Right now i’m using fitbit charge 4 and 5, oura, withings sleep, dreem 2 and manually asess my sleep every morning (before looking at any devices).
It would be really cool to make some sort of consensus score out of all of these devices! And perhaps it would be valuable to do some analysis where the agreement across all the devices (or between Dreem and the non-EEG devices) is used as a target feature. I’d be really interested to know what other factors cause the devices to disagree, as that would help get an understanding of how to “subtract away” some of the noise in sleep measurement.
When are you planning to show your next paper? I’m ready to read now
It may be quite a wait, I’m afraid I’m fairly burned out from the Quantified Sleep paper and am focussing on finishing my MSc thesis at the moment. In the near future, I’m going to try do some smaller-scale experiments that I can post here. I would like to do controlled (maybe self-blinded) experiments on the factors that were highlighted in the observational analyses.
I’ve also been wanting to do some analysis of my diet/nutrition. I’d design a two-week plan involving various different food types, quantities, timings, etc. Then track everything (calories, macros, timing) and relate it to data from a continuous glucose monitor and ketone strips.
I’m looking forward to your device agreement results (and the ones about spaced repetition’s effect on REM)! Keep it coming, Max!
This is a single night. I have nights where oura and dreem have good agreement, almost perfect. The problem is that most of all other nights agree less. Confusion matrix takes into account summary of all nights.
Lets look at deep sleep from confusion matrix from my previous post. There were a 12.3% of deep sleep according to PSG. Oura recognized 9.9% and misrecognized 10.2%. So PSG tells us there is 12.3% of deep sleep, but oura tell us there is 20.1%. If we take average night of 8 hours, PSG tells us there is 8*60*0.123 = 59 minutes of deep sleep, oura tells us there is 8*60*0.201 = 96.5 minutes of deep sleep. I dont see how that ~37 minute difference in deep sleep can be a “good” agreement, thats about ~40% of error. Same for rem.
Awake time even worse, oura tells there is 8*60*0.077 = 37 minutes awake, psg tells us there is 8*60*0.007 = 3 minutes. Since total sleep time is a time in bed minus awake time, we will get ~34 minute error in total sleep time (37-3). I dont see how overestimation of awake time by 34 minute is a good agreement?
There is metric called kappa, which is measure of agreement. In my case is was 0.42 for oura which is a low value, Rob didnt show kappa for his confusion matrix, but i’m confident it will be about same.
Yes. If i want to check what affects my awake time the error of 30 minutes looks pretty big. Same for deep or rem sleep. Total sleep time also have an error of ~30 minutes because of awake time error. If you have read Dreem 2 psg study, you may seen kappa of 0.74.
There is accuracy / comfort trade off. Like bias / variance one I see oura in a side of being pretty comfortable with a big price in accuracy. For example fitbit charge is less comfortable than oura, but agree better with eeg. Dreem is even less comfortable than fitbit, but outperforms non-eeg wearables.
5 sleep scientists had a 0.8 Cohen’s kappa according to dreem study. Each sleep specialist analyzed EEG signal data independently. That’s not perfect, but a solid agreement. There are some other studies with kappa like 0.76+ between sleep specialists. I’m not requiring oura to have 0.9 kappa, but 0.42 (in my case) is too small.
Why light/wake classification is less obvious? As i see all of sleep stages is a complex processes, which a rougly categorized. Some specialists says that sometimes its hard to classify some transition periods, which may cause loss of information. But anyway there is AASM standards for sleep stage classification which defines what we call deep sleep etc.
PSG utilize hr, hrv, respiratory rate (direct), temperature, muscle electrodes at legs, ecg, spo2, motion in addition to eeg, so there is a ton of sensors here)). Dreem 2 also have motion data, sonometer and ppg for hr. These devices arent just EEG. Zmax have even more sensors than dreem, adding spo2, hrv, temperature etc.
Do you have a gaps in your data? Sometimes oura shows a gaps in my data (1-2 days per week for 20-30 minutes), which can be treated as missing. I dont understand how they can tell that i was in rem sleep if there were no hr/hrv data?
Same here. It’s pretty comfortable.
Yeah, that’s comfort / accuracy trade off. I take my wearables / headband everywhere with me and it’s not a problem, so i have my flights etc. But that’s for me, most people will not tolerate this)
Also i’m not sure if these extreme days should be included into the model, because my current goal is to optimize my usual sleep, with less interest of extreme conditions (flights is less than 1% of my sleep).
That’s good point. I’m using oura for ~330 nights and i have about ~160 nights of dreem data. I’m a bit sad that i havent started this few years ago
Maybe, but i assume you dont have 500 nights of less noisy data to check that. I hope in a few years i can better understand if using headband will add some value over just using oura alone. But there is possibility that headband may not add anything at all.
Same throughts
Maybe. Since i have both devices, i’ll come with results when i have enought data. I’m not sure if even dreem can detect something if effect size is small. This may take a years to get enough data.
I just look at my fitbit when going to sleep, for example 23:15. When i wake up in the morning i look at fitbit at first. I’m dont remember a morning when i forgot yesterday bedtime So i’m pretty sure it’s even more accurate (but maybe i’m overconfident?)
After dealing with some psy questionnaires i’ve found that to get some useful data there should be a few questions about metric of interest. Single question things doesnt work well. I’m answering a set of a questions related to sleep issues which comes from pittsburgh sleep dairy. In my future post i’ll show full questionnaire results and how they correlate with headband / oura / fitbit (each of these devices have some degree of sleep disturbance measures).
I usually go sleep at 23:00 and wake up at 7:00. I dont spent any time in bed during day and immideately go out from bed when i wake up. My sleep quality and quantity described in details here.
I’ve had problems in the past with very long sleep onset (40-60 mins my brain can stop) which i was able to lower to 10-15 mins now which is a healthy range (most impact was caused by using dreem with their programs for improve sleep). My current sleep is mostly ok, but i want to lower my nightly awake time and awakenings count to be in a healthy range.
I was able to lower them in some degree by dealing with some external stressors (noise, overheating etc) but still waking up 2-3 times per night.
I’m not sure what this formula will describe. There is oura formula, also there is ZQ formula from zeo sleep. But what’s their clinical value? Single measure will lose some information. I understand practical value of this when i’m trying to build a model, but in general i prefer to look at all data i have
I tried to do that, but it’s hard to build 1 single number. I can for example build a sum of standartized awake time, awakenings count, position changes and call this a “disturbance” score. Maybe it’s worth adding here a sleep onset latency and call it “insomnia”. Another metric might be a sleep quantity which is something like deep/rem/light. The problem is these metrics cant be compared to anything except myself in the past. And i may be wrong and misinterpret them. That’s why for now i prefer looking at all data and use well estabilished metrics.
I think i can do that in a future. But results might not be generazable as most of n=1
It mightbe quality of sensors, quality of firmware, sleep detection algorhitms etc.
That will work only if oura have a lot of positive signal inside which is hidden by the noise. If it’s not - you can’t recover something that wasnt measured accurately. It measures hr, hrv, movement and temperature with an acceptable quality. I dont think that’s enough to describe sleep in all details as psg with all their sensors.
i have all of my nutrition for 13 months, but dont have enough stats skill to analyze this but i hope i can in a near future.
Thanks I think we can print our posts from this thread and apss a peer review
Yes. Right now i’m using fitbit charge 4 and 5, oura, withings sleep, dreem 2 and manually asess my sleep every morning (before looking at any devices). I’m planning to post my results soon. Using dreem as a reference device, manual asessment of total sleep time outperfroms other non-eeg devices (~60 nights of data), so i’m pretty sceptical on total sleep time from non-eeg wearables (we can think of brain as an eeg device ).
Thanks. Right now i have ~60 pairs of data. My total sleep time standard deviation is 46.2 minutes (dreem 2) and i want to be able to detect at least 10 minutes effect which is 10 / 46.2 = 0.22 of my standard deviation.
Simple power analysis suggests i need 164 nights (with 95% significance and 80% power), so it might take some time…
also i’m not sure what to do with multiple comparisons issue here, since there is a few devices, my p-values must be adjusted which may lead to even ~160 nights isnt enough
Preliminary data analysis of 63 nights is available now.
Withings Sleep analyzer and Manual assessment seems to be a good estimates of total sleep time (sum of DEEP, REM, LIGHT) and a proxy to EEG device. Fitbit Charge 4 is less accurate compared to manual assesment. Oura shows worst results.
Fitbit Charge 5 was not included since i’m using it only for 2 weeks, but FC5 agree with Dreem 2 pretty similarly as FC4 and i assume FC5 will have same results as FC4.
Time in bed (which is total sleep time plus time awake) seems to be fine between all devices.
Google spreadsheets with manual sleep asessment seems to be acceptable alternative to wearables for measuring total sleep time.
Analysis will be updated in future, when i gather more data.
I just had a look at these initial results. Three things came to mind:
In 6 months, I expect you’ll have some really robust results from this experiment. You should consider writing it up formally as a preprint and getting some feedback from the science teams at each device manufacturer.
I’m surprised that the Oura ring performs that badly compared to the other non-EEG devices. My priors are that a company successfully selling sleep-focussed wearables should be performing at least as well as companies selling general-purpose wearables (e.g. Fitbit). Perhaps the Oura ring is just overhyped, but perhaps there’s something else going on. In the latter case, if I had to guess, I’d imagine that the Oura ring’s performance might vary somewhat across individuals. How’s the fit of your ring? What size did you get and which finger do you wear it on? It seems there are quite some variables there that might have differed and may account for some of the inaccuracy. How often do you have a night where some data is missing? Quantified Scientist has also done some comparisons with two Oura rings on different fingers. IMO, going with the finger-worn device adds a lot more variables and Oura may need to gather more data to refine their usage recommendations.
In your Limitations section you say “manual assessment accuracy may be affected by calibration with wearables and learning.” I think this is an excellent point! I’d estimate that at least half of the value I get from manual tracking in QS experiments is from the mindfulness and intentionality that are involved in actively logging data. As someone who is clearly very focussed on their sleep and manually logs it daily (as well as checking various sensors), you’re probably way above average at estimating sleep duration. This speaks to the feedback loops that make (N-of-1) QS studies so difficult to interpret. I wonder if there would be any principled way to account for that in your experiments. Any ideas?
As always, keep up the great experiments and communication of results!
I’ll continue using Fitbit Charge 5, Withings Sleep, Dreem 2, Oura ring and manual asessment. Since i’m not familiar with writing scientific (only reading ) articles i’m not sure if i can do that alone. I’ll come back with that after some time, when data is gathered.
Same thing, right now i just updated my priors with new data… I dont understand what makes Fitbits be good at sleep tracking. I assume oura ring HR, HRV, accelerometer and temperature data is of good accuracy and it shouldnt be so far from Fitbit, which utilize same things to predict sleep…
Fit is perfect. There is no air between finger and ring, it sits pretty fine, without loosing. Before sleep i check orientation of ring and rotate it if needed.
Yeah, i’ve seen all of his videos. I’ve viewed multiple times ones related to oura / fitbit charge / dreem. Oura have some announcements soon, if it’s a new ring - i’ll preorder it and will wear both for some time.
Ring have some limitations due to small battery. As i hear there is scientific version with raw data access, but it doesnt seems available to consumers.
Also it may worth to note that my sleep looks healthy, the only thing i want to improve is awake time, but its not too big to be a problem. SPO2 ring didnt reveal any drops so i shoulnt have sleep apnea. It looks like i dont have serious sleep disorders. Since consumer wearables state that they were validated on people free of sleep disorders i assume they should work fine on me.
Install all apps on wife’s phone and let her sync all devices and do not allow me to look at results until experiment is finished. But i’m not sure if want to be blind for a few months
Also i can see that fitbit / withings not far from manual, so it might not worth overquantifying everything manually in long term.


 Actually i did that in some degree, but not in a solid way like you
Actually i did that in some degree, but not in a solid way like you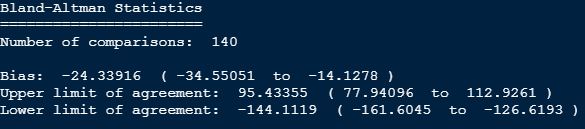

 My own experiences,
My own experiences, 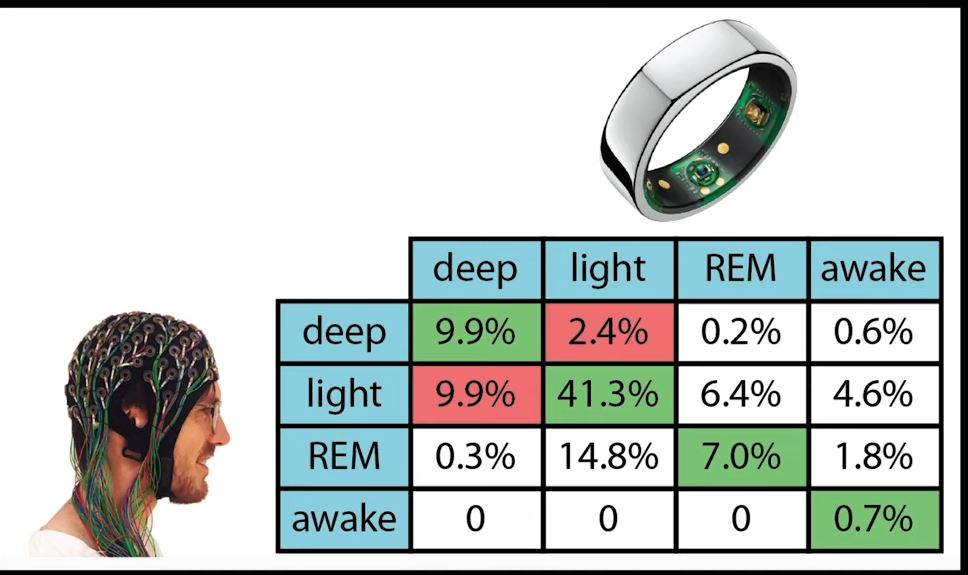
 I’m fairly burned out from the Quantified Sleep paper and am focussing on finishing
I’m fairly burned out from the Quantified Sleep paper and am focussing on finishing