pybit is a Python interface to the data collected by FitBit trackers. It uses the FitBit website to download steps and sleep data with 5 minutes and 1 minute intervals respectively. This software is still under development, and be aware that if the FitBit website changes, this software will break. This software is not using the documented API as it does not provide the intraday data, only daily totals.
It requires Python 3.2+ and matplotlib.
I’ll be working on this over Christmas so suggestions are welcome.
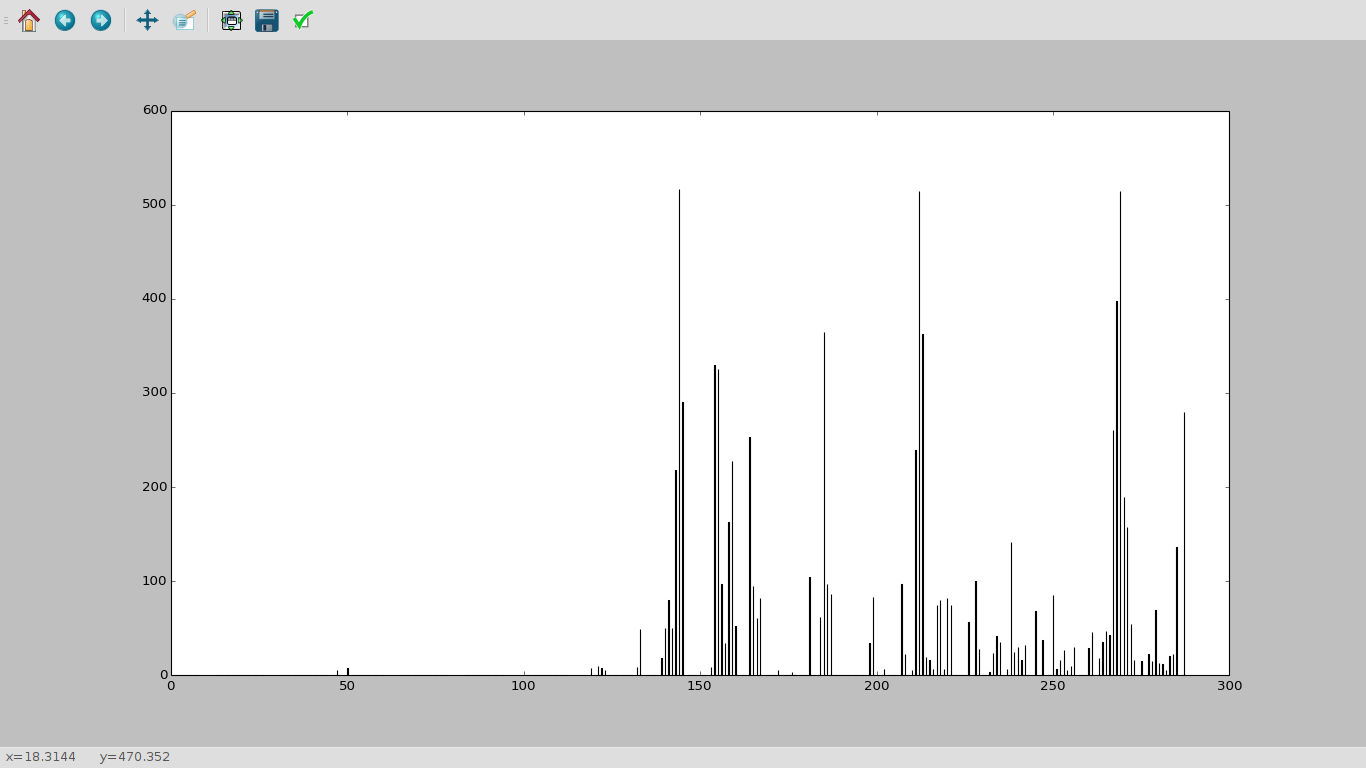
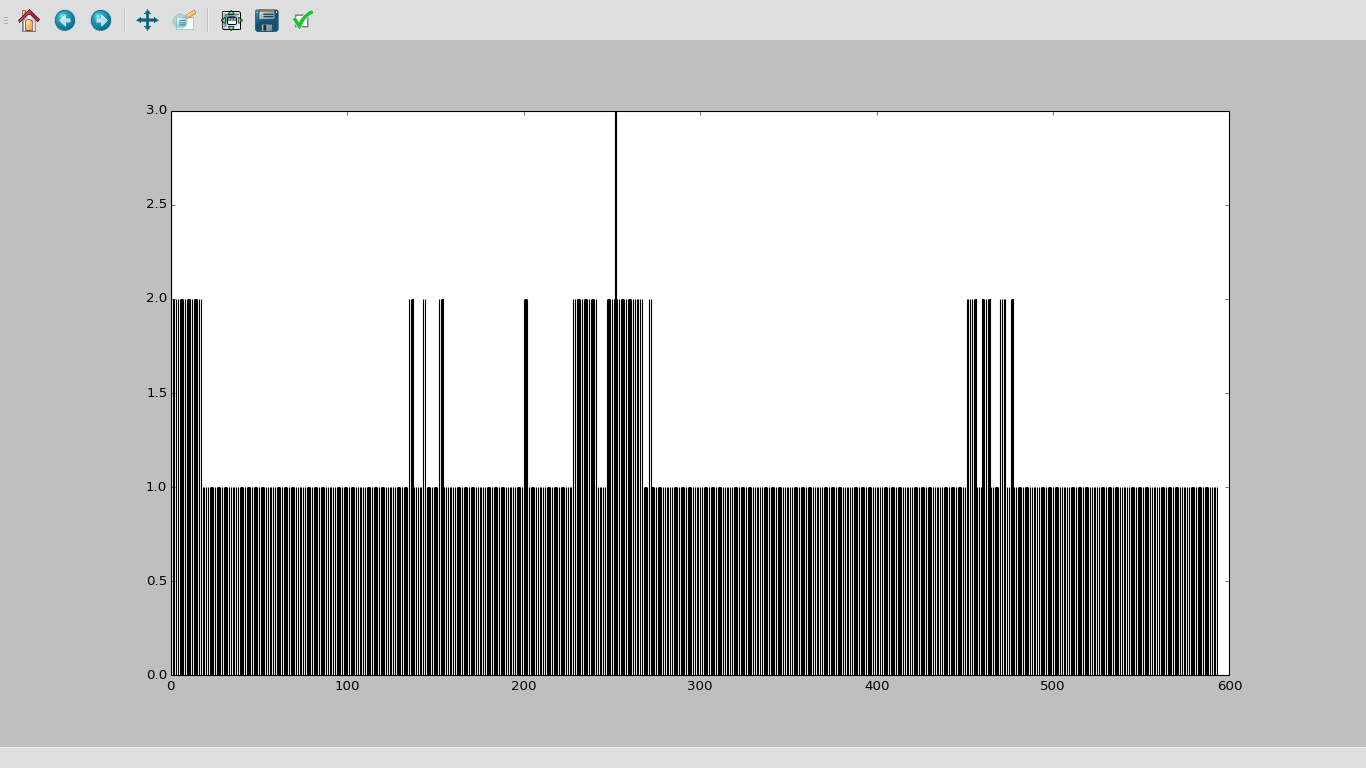
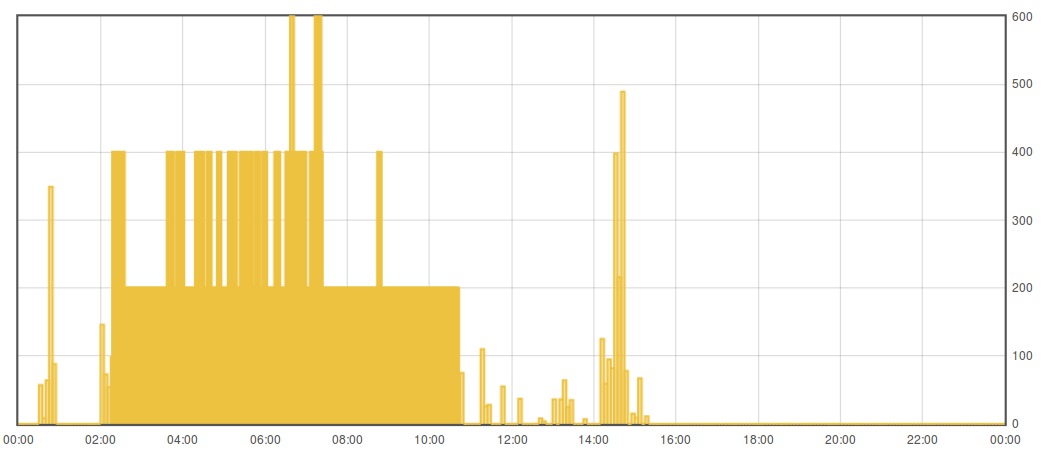
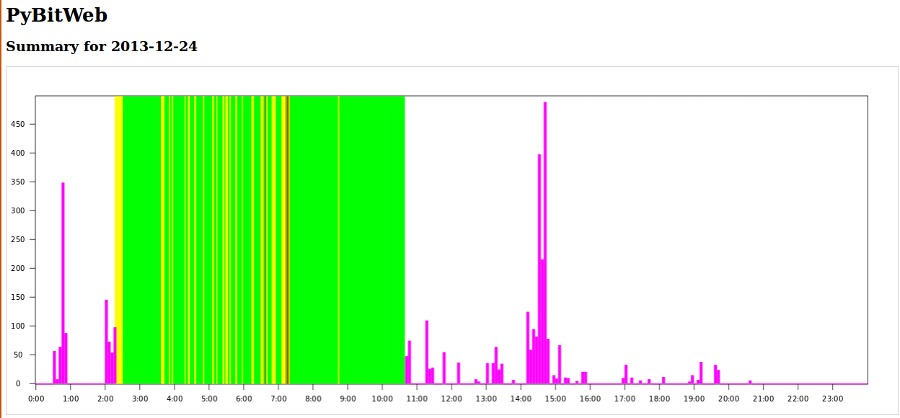
The first one is for a day of steps, the second for a night of sleep. I haven’t put much effort into the visualisations yet though, mainly just getting the data into a useful format.
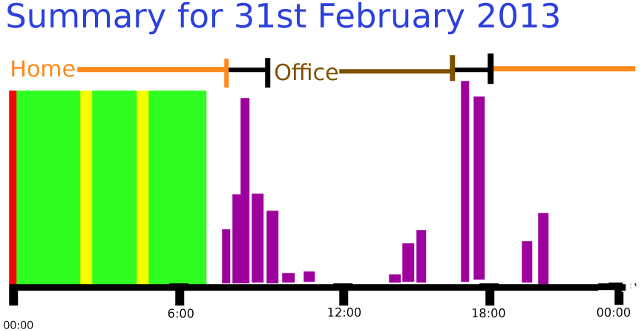
The vision is to produce something that looks like this:
Fitbit’s “Partner” API doesn’t seem like something that would be generally available, especially given that part of the vision for this software is that it’s something you can run yourself, it’s not a SaaS solution, so either everyone would need to ask Fitbit for it to be enabled or the key would need to be available which Fitbit wouldn’t be happy with.
It would be nice to have the increased resolution on the steps data, but the minute-by-minute sleep data is not available via the API even when the Partner API is used.
[quote=“irl, post:5, topic:834”]
[…] everyone would need to ask Fitbit for it to be enabled or the key would need to be available which Fitbit wouldn’t be happy with.[/quote]
Good point. This shows how it’s counter-productive to require people to jump through hoops to get access to the complete API. Such interactions should only be required for increasing quotas etc.
Thanks, I hadn’t seen that. I’ll add the sleep data fetching code to use the API soon then. I’ll probably keep the web scraping code though, as that doesn’t require a seperate authentication so might be useful to some people.