Hi all
I’m a biostatistician and I made a (free) web-app that I thought maybe someone here would find interesting. It’s at:
www.my-statistical-health.com
Right now it’s pretty beta, but it’s fully functional towards the goal of being to able to seriously analyse any type of self-quantification data. For my self I track stuff like fitness and diet-stuff. But anything goes really. I’d love feedback.
/Lasse
3 Likes
Oh, a bit too fast there. The example user ID was wrong. Should work now. Beta  . The example user btw is myself. The point of that investigation was because my wife always was on me with how much water, coffee, and tea I was drinking (“not right proportion!”). So I registered that count daily for a year, along with a number of outcome variables, various ailments etc (only some I put public), and then made the cross-correlation analysis, complete with delay-days. So for example if coffee would make me feel bad, even with a two-day time delay, then the analysis would catch that. But could equally well be used for more serious quantified self data. Bottomline: 1) while at it, I made it into an online analytics engine for free use, and 2) I’m allowed to drink coffee again
. The example user btw is myself. The point of that investigation was because my wife always was on me with how much water, coffee, and tea I was drinking (“not right proportion!”). So I registered that count daily for a year, along with a number of outcome variables, various ailments etc (only some I put public), and then made the cross-correlation analysis, complete with delay-days. So for example if coffee would make me feel bad, even with a two-day time delay, then the analysis would catch that. But could equally well be used for more serious quantified self data. Bottomline: 1) while at it, I made it into an online analytics engine for free use, and 2) I’m allowed to drink coffee again
What you have done is very interesting Lasse. I submitted your sample data and played with the analysis a little. This is going to take some time to consider and evaluate. Thank you for doing this. I can see it allowing a person to get a much better handle on probable cause/effect relationships in one’s own life. Yes, I know the caveat, correlation does not prove causation… But even so, in an n=1 setting it is a powerful tool.
Thanks again.
Thanks a lot. I forgot to mention that the code is open-source (here https://github.com/lassefolkersen/my-statistical-health) in case anyone want to contribute or discuss further.
And this causation vs correlation discussion. Yeah! It’s so important and so difficult at the same time. To other people reading this I want to really re-emphasise this point about stationary data and developments over time, that i noted. There’s a gazillion reasons why a correlation may not be a causation, but the most typical one is if something has a trend over time. If that’s not the case, e.g. you have to random wave-forms overlapping, then I’d call it ‘interesting’ at the very least. And if you have something interesting, then the next step is to conciously vary the levels of that ‘thing’ - whatever it may be - and test if it actually does control the outcome.
So what I mean is that if you observe something like this:
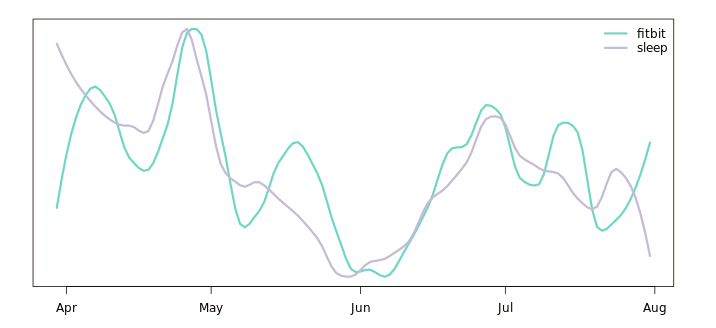
Then it seems that there is no overall trend over time, just fluctuations. When fitbit count is high, then sleep quality is also high. Randomly but correlating. Which is interesting. The intention is that if such thing is observed, and, say, sleep quality is important - then this is interesting. Then try to vary the fitbit count on purpose - walk less, walk more - and see if the sleep quality follows. That way causality can be established.
This site is super good! It’s a bit more complex than what you usually get in the polished apps, but once you get over that it’s fantastic in terms of actual insights. Real stats, not just app-pop-stats.
Thanks a LOT for making this!
1 Like
Great idea and it’s a very convenient tool, Lasse! Tried to find the correlation between coffee (I drink it a LOT during my shifts) and weight, but didn’t find “weight” as an option. Will it be added in future or I missed it?
Thanks a lot ! We have collected lots of data with a multi-factor self tracking app and I intend to compare various machine learning techniques this summer - It will be interesting to compare with a statistical analysis approach