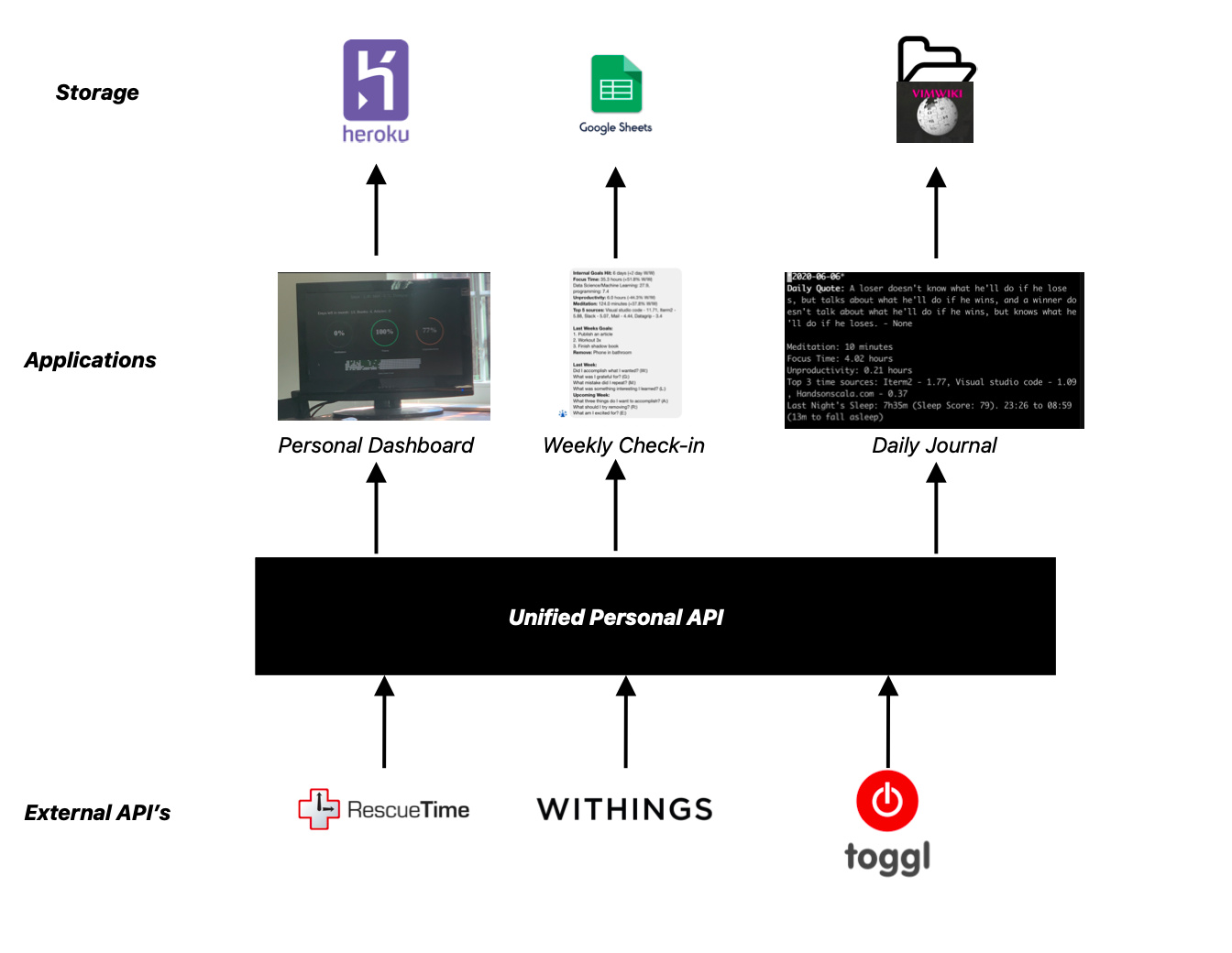
Here’s the open source dashboard I built 3 years ago and am still using today - https://github.com/Andreilys/personal_dashboard
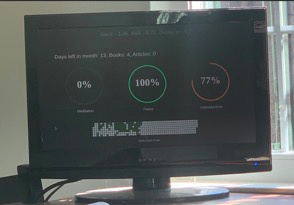
I ended up building this because I couldn’t find any dashboards that were real-time. This creates an annoying user experience where you need to actively refresh the dashboard/app to get your latest data. I wanted to be able to, at a glance, see how my day has been going and make corrections accordingly which is what I was able to accomplish with a combo of javascript long polling and flask.
I’m actually planning on rewriting the whole project and creating a micro-service for the API which will act as an interface for a bunch of my other projects that rely on this data. So if you want to collaborate feel free to email me - andreilyskov [at] gmail [dot] com