Why am I posting this?
- Enhance commitment to following my study protocol
- Comments! You guys are sharp – I’d love to increase validity of my results by improving study design.
I will start data collection in 3 days (the 11th of October, 2018). It will continue until the 21st of October.
Preface
I track time spent using my calendar, syncing it to Timely for insights.
Once a day, I review my entries. I look specifically for entries that went better or worse than expected, or took longer or shorter than planned. This allows me to ensure that I repeat whatever made the task go well, and avoid what went it go worse.
Why are you doing the action you’re experimenting with?
I do daily reviews to:
- Generate insights
- How to optimise routines
- Which actions matter most to me
- Feel better
- Feel like I accomplished something
- Feel happy
How can you observe the effect of this?
- Quality of tasks/insights added to Todoist
- Emotional state after review
- Emotional state the day after review
- Time spent on review
What’s the best way of measuring it?
Randomised controlled trial (RCT), days are cluster-randomised (cluster size 5) into either voice- or written review. All analyses will be completed as “intention to treat”. Adherence will be quantified as %. No preliminary analyses will be completed.
Insights
To measure 1., I will make an excel list of insights. I will rate all of them at the end of the experiment, blinding myself partially (randomising order and hiding which intervention was randomised to).
I will send the table, in a blinded form, to:
- Dad
- Girlfriend
- Best friend
With rating scheme (-5 to +5) as so:

Points will be rating squared. The metric will be % of total points awarded by rater.
I will compare interventions by rating squared as a continuous variable.
I expect normal distribution and will do Z-tests for P-values.
Emotional state
I will track my emotional state three times a day (semi-randomly) and right before I go to sleep using Reporter (iOS).
Outcome: Mood-level on the evening of review and the day after.
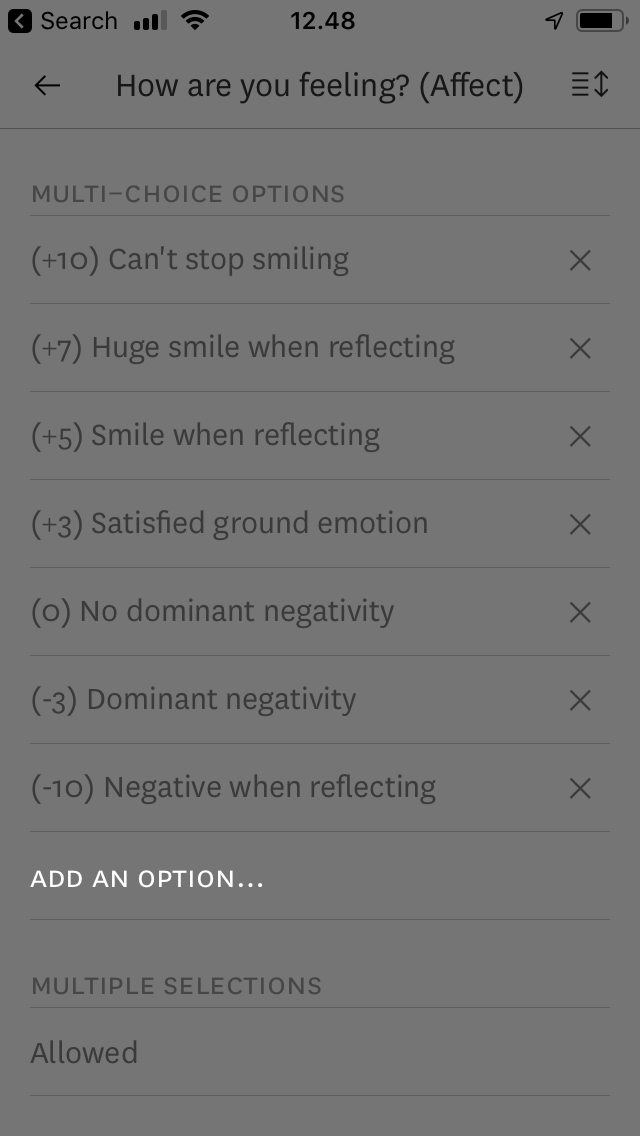
I will also use HRV data from my Apple Watch as a continuous outcome.
Completion proportion
Self-explanatory
Cohen’s d
All results will also be reported as Cohen’s d.
Please let me know what you think, and if you have any suggestions for improving the study 