Hi,
since Gary told me I need to be more specific I am going to post my first significant findings.
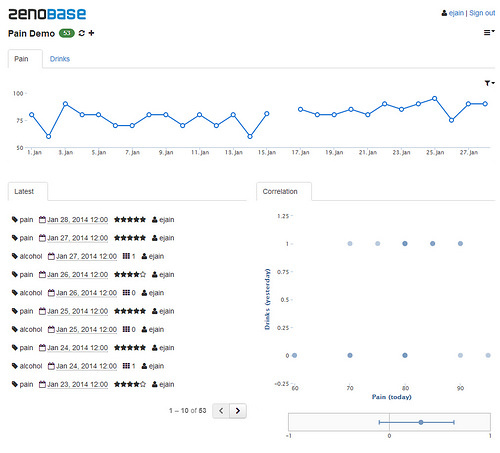
I recorded my pain on a scale from 0 to 1, like percentage.
I also recorded whether I drank alcohol on that day. And set up a variable whether I drank the day before
Model Summary (E_Painscale)
╔══════════╦════════╤═════════════════╤══════════════════════════╗
║ R-Quadrat║R Square│Adjusted R Square│Std. Error of the Estimate║
╠╤═════════╬════════╪═════════════════╪══════════════════════════╣
║│ ,45║ ,20│ ,13│ ,10║
╚╧═════════╩════════╧═════════════════╧══════════════════════════╝
ANOVA (E_Painscale)
╔═══════════╦══════════════╤══╤═══════════╤════╤════════════╗
║ ║Sum of Squares │df │ Mean Square│ F │ Significance║
╠╤══════════╬══════════════╪══╪═══════════╪════╪════════════╣
║│ Regression║ ,06│ 2│ ,03│2,74│ ,09║
║│ Residual ║ ,24│22│ ,01│ │ ║
║│ Total ║ ,30│24│ │ │ ║
╚╧══════════╩══════════════╧══╧═══════════╧════╧════════════╝
Coefficients (E_Painscale)
╔════════════╦════╤══════════╤════╤═════╤════════════╗
║ ║ B │Std. Error│Beta│ t │Significance║
╠╤═══════════╬════╪══════════╪════╪═════╪════════════╣
║│ (Constant) ║ ,18│ ,03│ ,00│ 6,82│ ,00║
║│ V_Alk ║-,10│ ,05│-,40│-2,12│ ,05║
║│ v_alkvortag║-,04│ ,05│-,16│ -,86│ ,40║
╚╧═══════════╩════╧══════════╧════╧═════╧════════════╝
I used PSPP and linear regression as method. I have now 27 records.
To me it looks interesting, that v_Alk, meaning alcohol consumption the same day, is more significant then alcohol the day before. Leading to the question whether I drink because of the pain? I would habe expected to have the pain the other day, so after drinking alcohol.
So what do you guys think? It that method here used correctly?
I also get a significance of 0.07 for alcohol and acid burning in my throat (how do you call that in english). This one is easy understandable.