I’ve been talking with QS friends and colleagues about how to represent QS data flows so that our ongoing conversation about access can be supported by better information about real cases. The link at the bottom of this post goes to a .pdf of some draft diagrams. I’d be grateful for any feedback. Corrections of errors and comment on the design are equally welcome. If you want to use this approach to make your own diagrams, feel free. We hope you will share your knowledge.
The diagrams are meant to be helpful in two ways. First, they contain reported detail about data access procedures in a sample set of self-tracking systems, selected to expose a range of approaches, and organized by commercial brand. Second, and more importantly, they offer a conceptual model of data flows that can be used by others, including tool makers themselves, to understand and express how self-trackers and researchers may be able to access self-collected data.
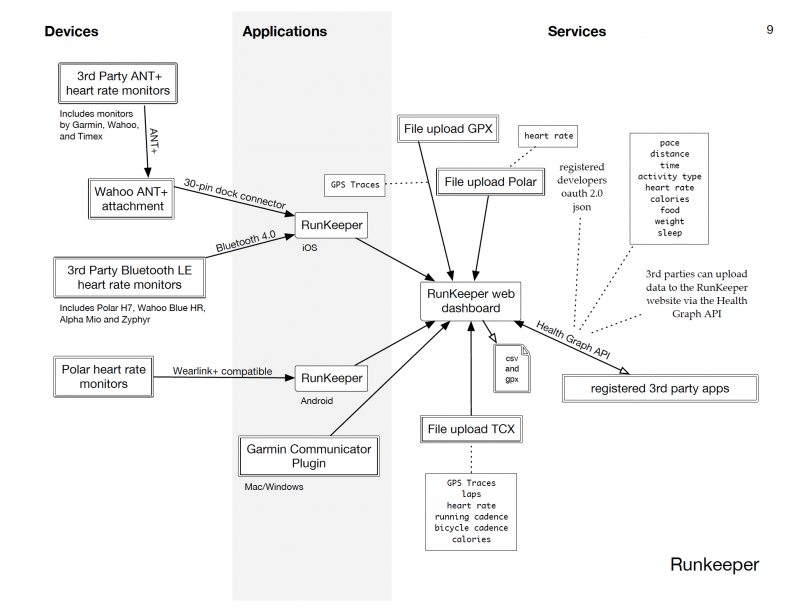
The best way to begin reading the diagrams is by following the data from left to right as it flows through three technological “zones”: Devices, Applications, Services.
A device is an application specific computer, such as an activity tracker. These include the bands, straps, scales, and other gizmos familiar to all of us. It’s important to remember that even little toy-like trackers in a colorful plastic coating are in fact computers running software, and the measurements they make are influenced both by the electromechanical systems they contain and by the software they run. We consider something a device if the software it runs is “baked into” the instrument, perhaps updatable by the vendor remotely but normally invisible to the user.
An application is software running on a general purpose personal computer, where personal computer includes smart phone, tablet, or traditional PC. Increasingly, self-tracking applications can use the native sensors installed in the platform, as iOS applications can use Apple’s M7 chip. Thus self-tracking data flows may not originate in external devices, but instead originate in the application zone.
A service is software running on a vendor’s infrastructure. Most opportunities, though not all, for pulling data out of a commercial ecosystem occur in the service zone. Services are normally accessed by users through web sites, and by 3rd party developers through APIs. Importantly, self-trackers can also add data to a system via a web site, so that new measurements can enter the system from the service zone.
Data types available through a vender’s API are represented on the diagram as boxed text. How temptingly simple these boxes appear! But by following the lines of the diagram backward, the underlying complexity of the data becomes visible. We hope these diagrams will support critical reflection on the common belief that improving access to self-collected data through common APIs, aggregation schemes, and measurement standards will satisfy research needs. Simplicity of access is a dangerous simplicity when it silently erases the provenance of the data. Our diagrams aim to illustrate some of the places where provenance is relevant.
Questions that these diagrams can help answer include:
Can I upload data from a particular device directly into a web site without going through a smartphone?
Can a single data type (steps, for instance) accessed via this API represent measurements made by different devices?
Can data accessed via the API include data from more than one service?
Diagrams downloadable here: http://quantifiedself.com/wp-content/uploads/2014/04/API-Diagrams-Production-Final.pdf
Sample diagrams include: Apple M7, Azumio, BodyMedia, Fitbit, Foursquare, Jawbone UP, Nike, Rescuetime, Runkeeper, Samsung S Health, Sleep Cycle, Withings.
The diagrams were conceived and designed by Robin Barooah, and researched and drawn by Steven Jonas. We are grateful to Intel Labs and the Robert Wood Johnson Foundation for supporting our research, and to the self-trackers and tool makers in the QS Community for sharing their knowledge.


