Over the past couple of days I have been actively building a software program referred to simply as the, “Generic Text Analyzer”. This program, according to the README.md file in the GitHub repo,
…performs a comprehensive analysis of .txt files found in the input directory by extracting linguistic insights and visualizations. It reads each text file, preprocesses the content and generates frequency counts for words, n-grams, parts of speech, named entities and TF-IDF scores.
The same description continues,
This program calculates readability metrics and sentiment, performs topic modeling using LDA and visualizes results through word clouds and bar charts. A detailed report is saved as a text file, and the content is also summarized using Anthropic’s Claude API. All outputs, including vsualizations and summaries, are stored in the output directory.
To put this all to the test, I collected transcripts from 300+ YouTube videos (published in the past 30 days) related to cybersecurity, homelabs and the tech job market. I then ran that .txt file through my program.
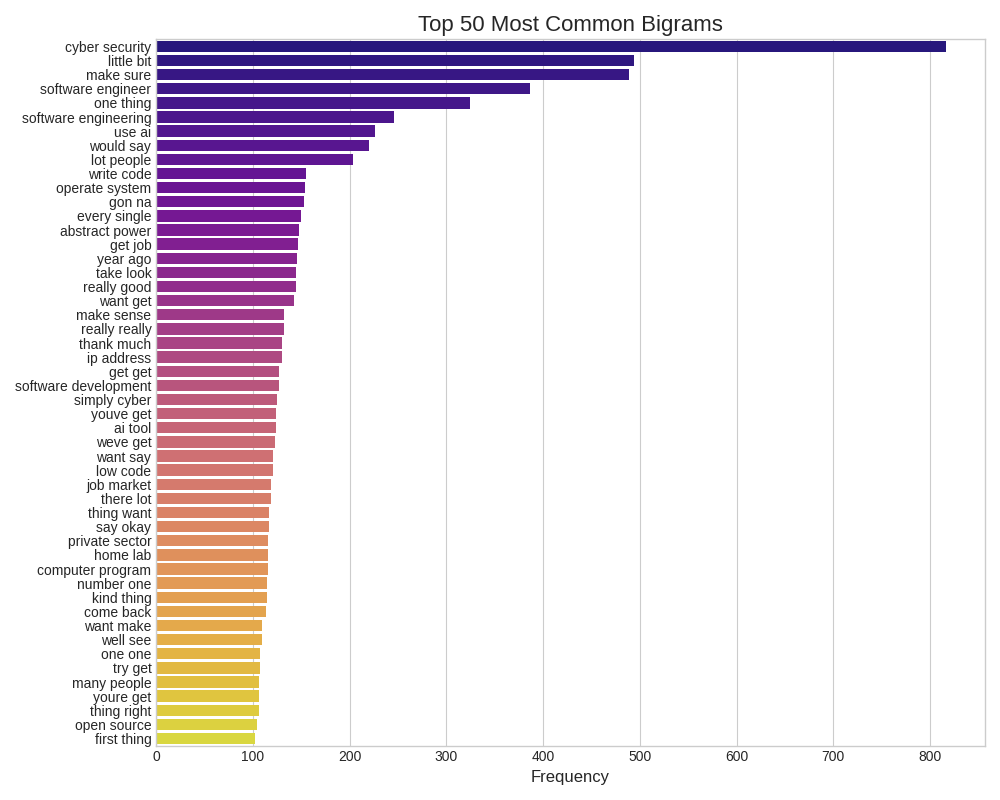
As part of the output, three images were/are generated. The first visualization is a bar graph displaying the most common 50 bigrams.
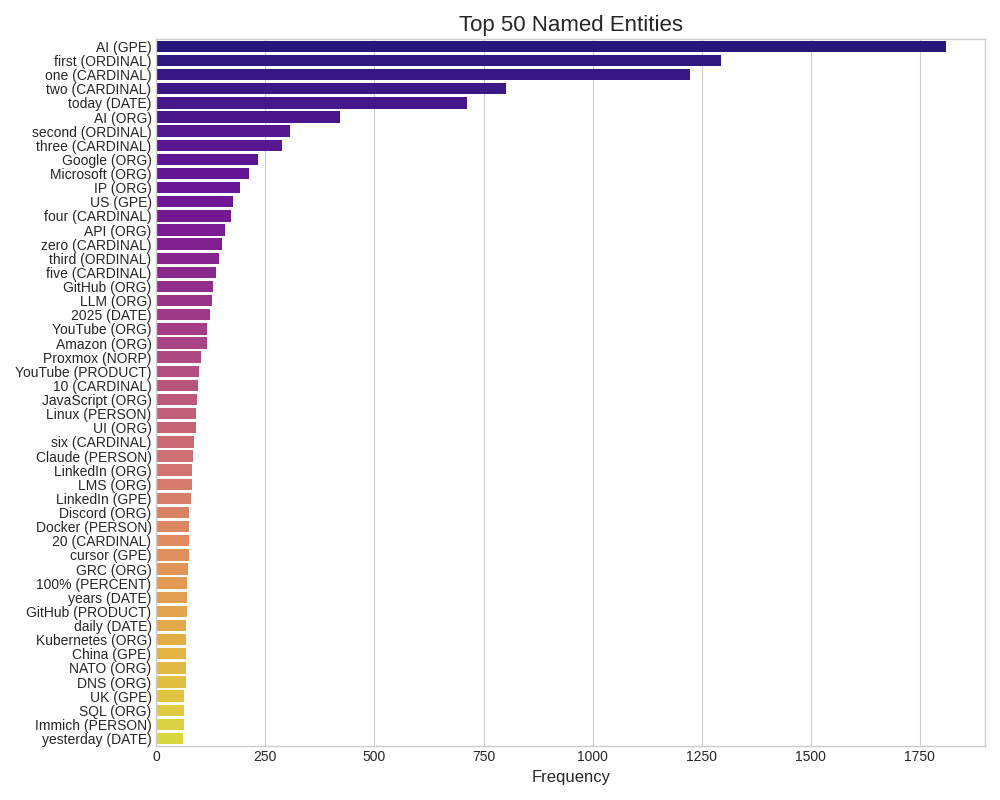
And the second image is a similar bar graph, but of the top 50 named entities most commonly referred to throughout all of the text.
In addition to the visualizations, my program produces a significant text-based analysis/report, featuring real-world metrics. Ultimately, all of this is done in an effort to understand the core message a body of text has by using the Python programming language.
Let’s programmatically turn 6MB of data into a 9.7 KB summary.
Along these lines, below you can find the .txt file my Python program produced after crunching 1.2 million words taken from YouTube video transcripts:
transcripts_enhanced_analysis_report.txt (9.7 KB)
Moving forward a little further. I submitted the Python analysis (the .txt file) to Anthropic. Which returned to me a breakdown of my prompt’s significance. Or, what hundreds of measurements mean, from an AI’s perspective.
I then took all three of these assets, the (1) original 6MB transcripts file, (2) Python analysis and (3) Anthropic summary, and fed them to ChatGPT. After following through with this chain of communication, I asked ChatGPT the following question, “What paradigm shifting changes or realizations can come from these notes?”
Here are the six (IMO) quintessential points/observations printed onto my screen tonight:
- The generalist is dead. Contextual specialization is the new entry point.
- Certifications aren’t proof, they’re permission to get noticed.
- AI isn’t a tool you use, it’s a collaborator you must supervise.
- Security is not a department, it’s a design principle.
- Remote-first is not just location; it’s visibility, autonomy, and proof of impact.
- The biggest risk isn’t AI replacing you, it’s not learning to work alongside it.
These points match up closely with my own observations and recent experiences in the world(s) of technology and job seeking. And in some surprisingly accurate and poignant/sharp ways.
The reason why I am posting this walkthrough here is because (I think) it demonstrates how (1) old-fashion data crunching using Python, (2) a little gumshoe work for sourcing the YouTube transcripts and (3) two AI tools can produce near-intimate levels of relevance with their outputs. Without knowing much about who I am. Making the self-quantification happening here both personal and social.
I hope this kind of odd software project is of interest to you.