I have an idea for a QS application platform and I’d like to hear your thoughts.
The idea is this:
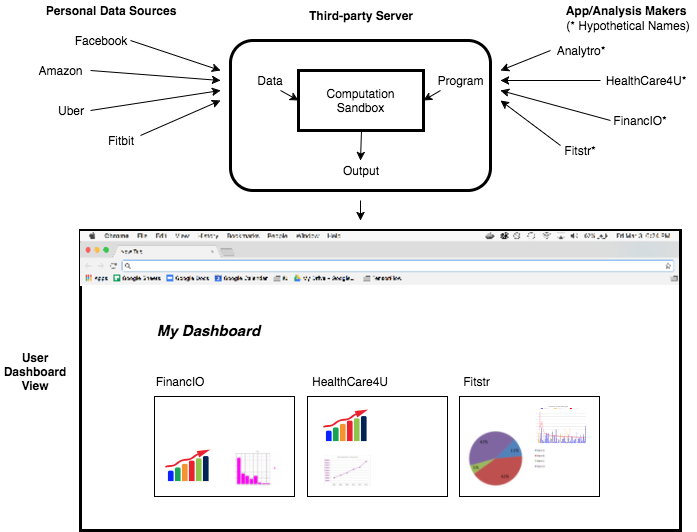
There are several applications out there for connecting your data from multiple sources via APIs. This makes aggregating the data easy, but after connecting everything you end up with a limited set of tools/analyses. What if there was a place that made it easy to connect your data, but you could use analyses written by a community of other people. It would be like the Apple App Store but for personal data analytics – and you never give your data to the person who wrote the app.
From the User’s Perspective:
A user wants to find correlations between Fitbit and Uber. They go to this new website and connect those two sources. Then from the Store on that website, they look for apps published that does that.
From the Developer’s Perspective:
A developer has been using the website for a while but there are no apps on the Store that analyze Facebook and Twitter data together. So she decides to write one. Using her own data in the proper format downloaded from the website, she writes a Python script that produces some output, making sure that the output fits a predetermined form (e.g. a JSON object with a Name and two integer arrays). Then she uploads her app to the website’s Store. Now she can use here analysis whenever she wants, and other users can use it too (she could also charge other users, just like Apple’s App Store). Even further, the output of her analysis can be used as INPUT to other developer’s analyses.
That’s an awesome idea for a platform, though one problem I see with it is the difficulty they might have starting the community. The app development requires a significant programming skill set. Regular users won’t sign up if there are no good apps, and there won’t be a lot of good apps if there are no users.
I think a more focused approach (on QSers and the skills that many QSers have) might generate a smaller community initially, but one that is very involved.
Another big problem is security. A centralized trusted-third-party is one way to go and better than spreading your data everywhere, but ideally you’d want to circumvent that. I’ve been thinking about trying to eventually implement a homomorphic encryption / secure multi-party computation / blockchain architecture similar to the one in this MIT paper. Anyone have any thoughts on that?
One of the challenges is integrating the information in a meaningful way. Apple Health does this by (I assume) defining a semantic layer (schema, taxonomy, ontology, logical data model, name your poison) which provides the structure of the data store. The transformation tools use this schema as the target structure for data that is onboarded, linking data of similar types but from disparate devices. Schema.org is home to an extensible schema that many organizations use as a starting point. I’m not aware of any QS schema - maybe somebody else is? Maybe Apple has made their schema public, but that would be just for personal biometrics domain.
There are other considerations and ways to expand the functionality, drop me a note if you’d like to discuss further.
Cozy - I hadn’t come across that, thanks for the link @Qek.
I like this idea, but if one of the main goals is data privacy / security, then hosting everyone’s data in a ‘trusted-third-party’ app seems like the weak link.
What about a solution that focused on easing the distribution of analytic modules to individual users who each host their own data on their own servers (Amazon, Google, private cloud). With a standardized data format, plugins could be written by the developer community to do custom data slicing / analytics / visualization, and then distributed on node/npm or pypi.
An incredibly superficial example of this is the React life by weeks timeline component i created for the Flow dashboard. It sits as a separate npm module and can be installed by anyone, and then plugged into any React-based UI. All it requires is access to JSON data in the expected format.
Such components, with the right API standards, could make requests to any server, perform processing, and display results. Installing modules or components still requires a little bit of technical knowledge, but with an interface layer on top of this process, it could be made to be “drag and drop” for the non-technical as well.
This is an interesting conversation that, to me, covers some often-discussed issues in a well structured way. If you follow @bkitz’s reference to Apple Health toward the place where it intersects with @ejain’s last comment about developers being more interested in platforms than apps, you will find yourself standing at the crux of the problem. Any system that can bring the vastly heterogeneous “QS data” into a common analytical framework is going to be a major technical resource for the world, with all the attendant costs and responsibilities. When @bkitz says that “…transformation tools use this schema as the target structure for data that is onboarded,” this indirectly says something about the strength of Apple’s approach. If you begin with high credibility as a platform operator, you don’t necessarily have to build transformation tools for all data sources, which is a horrid job in the liquid, ever changing environment of QS tools. Instead, the schema becomes a target for external toolmakers using the SDK.
Another approach comes from Open MHealth, a kind of open platform for schemas. This approach is really hard, as it requires people to have a lot of motivation for participation, but they’ve hung in there, I think because they are connected to academic researchers who were building their own transformation tools anyway.
Yes, i think you are right, and this is where the value is. As @bkitz mentioned, there are many tools (fast commoditizing) to pull in, aggregate and analyze data in very powerful ways, from Tableau, to PowerBI, to Google Data Studio and more. What doesn’t exist in these tools is a way to “drag in” a reliable machine learning algorithms to predict glucose or stress levels given a good set of feature data for example.
The funny thing with self-tracking is that, because the data is so personal, it is much harder to convince people to share it with an an online service provider. A compelling library of proven well-being related ML algorithms will serve as bait for those reluctant to share their data. The idea mentioned by @JeremyGordon offers a good option to overcome the confidentiality issues while still benefiting from a market for QS algorithms - worth exploring that one…
The challenge with such a market is how to abstract the algorithms so they work across individuals. I have been analyzing my family’s self-tracking data using PowerBI and Python for two years and any value i get from them depends heavily on my knowledge of the environment and context surrounding our day-to-day lives, which is not necessarily codified in the data i collect, for example.
@Agaricus mentions Open MHealth and I agree they seem pretty good. I am also defining my own if any one is interested.